
We Ran 52 AI Coding Benchmarks. Here's Every Uncomfortable Thing We Found.
CONTRACT.md cuts cost 54%, raises quality from 5/10 to 9/10. Agent Teams cost 124% more with no gain. Retry loops degrade output. 52 controlled runs, full data open-sourced.
UpGPT Team
UpGPT·April 20, 2026·12 min read
Why We Did This
This is the full technical version — every test, every table, every methodology detail. If you need the decision-maker summary, it's here.
We had just run 25 parallel AI workers across 7 swarms simultaneously and produced 12,500 lines of code across 96 files in 36 minutes. We had no idea what it cost. We hadn't measured quality. We'd just shipped fast.
So we ran a benchmark. Then another. Then 50 more.
What started as "let's figure out if parallel workers are worth it" turned into a set of findings that overturned almost every assumption we started with.
What We Tested
Task types:
- T3 — Notes CRUD: SQL migration + TypeScript types + 2 API routes + Vitest tests. 3 workers. Small-to-medium.
- T6 — Notifications system: large greenfield. 8 workers. Complex.
- T7 — SMS refactor: modifying existing code. Pure edit.
Approaches:
- V1 — minimal, vague prompts. Workers guess at interfaces and import paths.
- V2 — CONTRACT.md added: workers get exact interfaces, column names, import paths, SQL conventions upfront.
- NS — V2 with self-evolution: worker checks its own output and retries if it falls short.
- NSX — V2 with cross-model verification: Opus reads the worker's output and writes line-level critique before retry.
- V2O — V2 with a one-shot Opus review pass at the end (no retry loop — just a targeted surgical edit).
Architecture comparisons: Sequential · UpCommander (tmux workers) · Agent Teams (Anthropic native sub-agents)
Independent variables: CONTRACT.md on/off, architecture type, model (Haiku/Sonnet/Opus), grader (Opus/GPT-4o/Gemini).
Finding 1: CONTRACT.md is the entire game
A structured brief before the task — exact TypeScript interfaces, exact column names, exact import paths, SQL conventions, explicit non-goals — made the single largest difference of anything we tested.
2×2 factorial experiment (20 controlled runs):

The CONTRACT.md effect: -65% cost, -68% time, quality from 5 to 9/10. Architecture was secondary. Same model, same codebase, just a different document.
What goes in the brief that matters:
## CONTRACT.md
### Interfaces
interface Note {
id: string;
user_id: string;
content: string;
created_at: string;
}
### Database
Table: platform.notes
Columns: id (uuid), user_id (uuid FK auth.users), content (text), created_at (timestamptz)
SQL conventions: CREATE TABLE IF NOT EXISTS, no DROP POLICY
### Import paths
Types: @/lib/platform/notes/types
Supabase client: @/lib/supabase-server (server components)
### Non-goals
- No pagination in this PR
- No soft delete
- No full-text searchWorkers stop exploring and start executing.
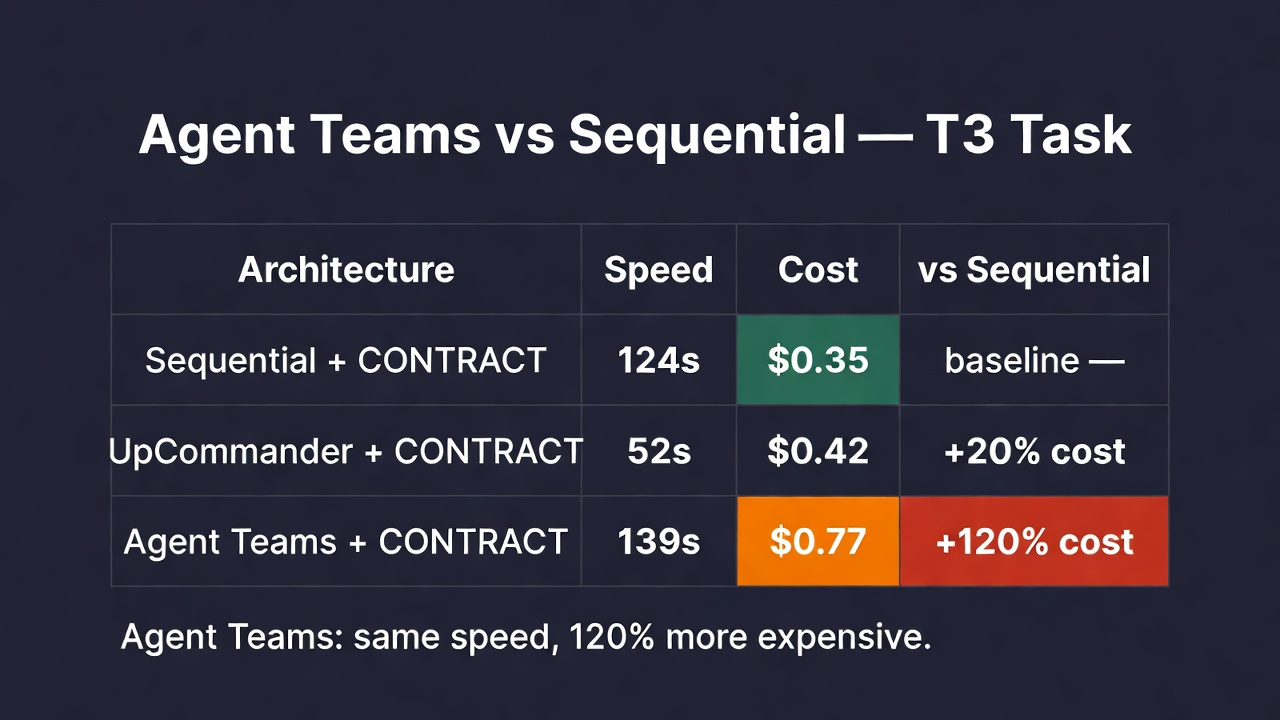
Finding 2: Agent Teams cost 73–124% more with zero quality gain
Anthropic markets Agent Teams as a way to parallelize work. Technically true. The data:
T6 (large task) results:

Every agent loads the full codebase context independently. Three agents = three copies of your 80K-token context. The cache burn dominates. Agent Teams never wins on cost. Sequential + CONTRACT wins cost every time.
Finding 3: Retry loops make the output worse
We wanted to test whether self-improvement retry loops could fix incorrect output without degrading quality. We built one and ran it.
N=5 on T3 with deliberate traps (wrong import paths, missing exports):
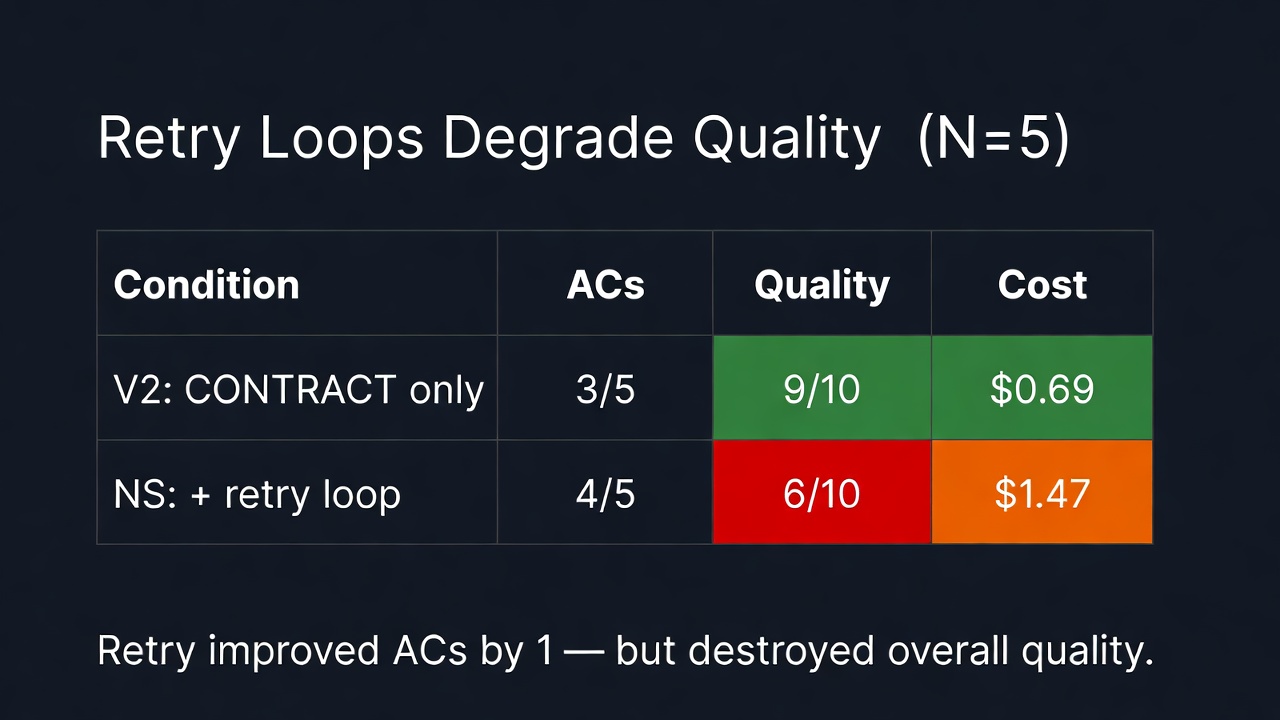
Self-evolution improved acceptance criteria by 1 item but degraded overall quality from 9/10 to 6/10 and cost 2.1× more.
Why? The model doesn't make surgical edits. It regenerates entire files. Fixing a broken import path means rewriting the whole route file — and losing all the CRUD endpoints and tests that were correct the first time. We observed this across every single retry attempt across 3 runs. It never didn't happen.
There's also a ceiling: the model cannot see the blindspot it keeps creating. Every run, every retry, stalled at exactly 4/5 ACs. The 5th requirement never resolved regardless of how specific the hint was.
NS-run-1: Fix import path → regenerates route.ts → loses 3 endpoints → 4/5 ACs, 6/10
NS-run-2: Fix import path → regenerates route.ts → loses 3 endpoints → 4/5 ACs, 6/10
...same pattern, 15 retry attempts across 3 runsDon't use retry loops for code generation. The architecture is the problem.
Replication caveat: this is one codebase, one model family, greenfield TypeScript tasks. The failure mode (whole-file regeneration on retry) may not appear in every setup.
Finding 4: Opus one-shot review adds nothing when the contract is good
We tested V2O (V2 + Opus reads the full output and makes surgical edits — not a retry loop, just a targeted one-shot patch):
Clean N=5 retest (full file context, no truncation):

Zero quality gain. +56% cost. When the CONTRACT.md is well-formed, Sonnet already reaches 9.8/10 — there's nothing for Opus to fix.
The lesson: Write the contract right. Don't retry. Don't add a review pass. The brief is the quality lever.
Finding 5: AST compression cuts tokens 91%
CONTRACT generation for refactoring tasks was expensive — the generator had to read the entire codebase ($0.36 vs $0.15–0.17 for greenfield). We adapted the AST-summary approach from agora-code: tree-sitter parsing, export-only extraction, cached by git blob SHA.
Results on 28 production files:

118x compression. For a large T6 session: baseline $5.45 → $0.85 stacked with CONTRACT.md. Zero quality tradeoff.
Finding 6: Haiku can implement a Sonnet-written contract at near-parity — but can't write the contract itself
We originally reported Haiku at near-Sonnet parity when given an identical CONTRACT.md. That finding stands — for implementation. But when we tested Haiku as the contract author, quality collapsed.
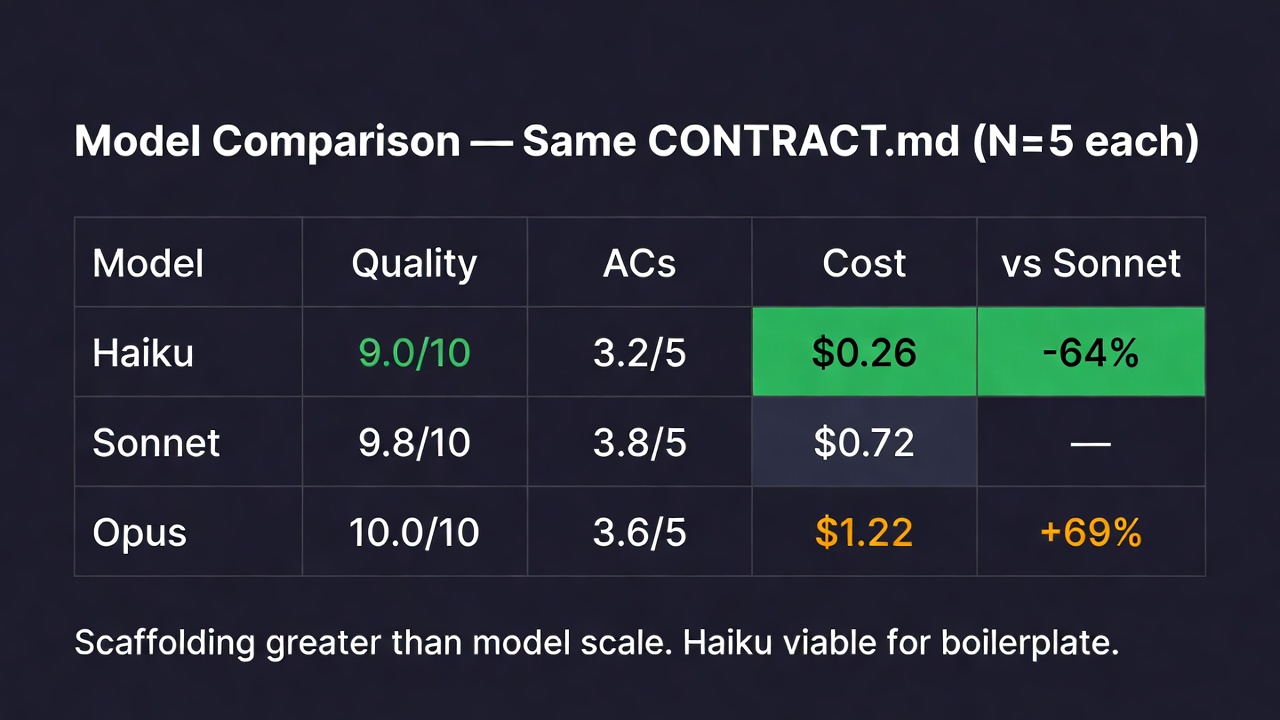
Follow-up V4 test (N=3):
- E (3× Haiku workers + Sonnet-written contract): $0.67/run, 104s, 7.9/10 — cost parity with all-Sonnet, slight speed gain
- G (3× Haiku workers + Haiku-written contract): $0.42/run, 75s, 4.9/10 — quality collapse
Haiku doesn't generate adequate contracts. The model misses integration hooks, picks the wrong DB client, omits non-obvious constraints. Sonnet catches these because it carries more codebase inference in its training.
Corrected rule: Use Sonnet to write the contract, Haiku to implement against it. That combo matches all-Sonnet cost with a small speed gain. Never let Haiku author contracts for multi-file work. All-Haiku is not the cost play it looks like in isolation.
Implication: For boilerplate workers in multi-worker sessions, route Haiku for implementation only. Route Sonnet for contract generation and design decisions.
Finding 7: Cross-vendor grading agrees within ±1 point
All quality scoring in this project uses Opus as the grader. We validated this by grading the same 5 V2 outputs with three model families simultaneously:

Cross-vendor spread: ±1.0 pts. Opus grading is directionally reliable. Gemini is systematically stricter and catches issues the others miss (unused NoteListOptions in the test file) — worth adding to production quality pipelines.
Finding 8: The index is a tree, not a flat dump — L0 → L1 → L2

The single biggest behavioral win in the second research cycle wasn't a new finding — it was operationalizing one: we treat the codebase index as a drill-down tree, not a monolithic file.
- L0 —
.codebase-index-l0.json(~18KB). One-line per module: what exists, what it exports. Always loaded first. ~4K tokens. Replaces 50–200K tokens of blind Glob/Grep. - L1 —
.codebase-index/<module-slug>.json(2–3KB each). Per-module: exact method signatures, import paths. Loaded only for modules the task touches. - L2 — raw source file. Loaded only when behavior (not just shape) matters.
The tree shape is the point. On a 600K-token codebase, a flat dump is a cache grenade. Drilling by level means the worker pulls in only what the current task needs. Generating the tree is a one-shot script — ours runs via pre-commit hook on every src/ change, so the index never goes stale.
This changed how we author contracts. Before: "read the whole repo, guess at signatures." Now: read L0, identify 3–4 relevant modules, read their L1 files, copy-paste exact signatures into CONTRACT.md. Contract quality went up, contract generation cost dropped.
Finding 9: L1 for discovery, L2 for implementation (N=1 early learning)
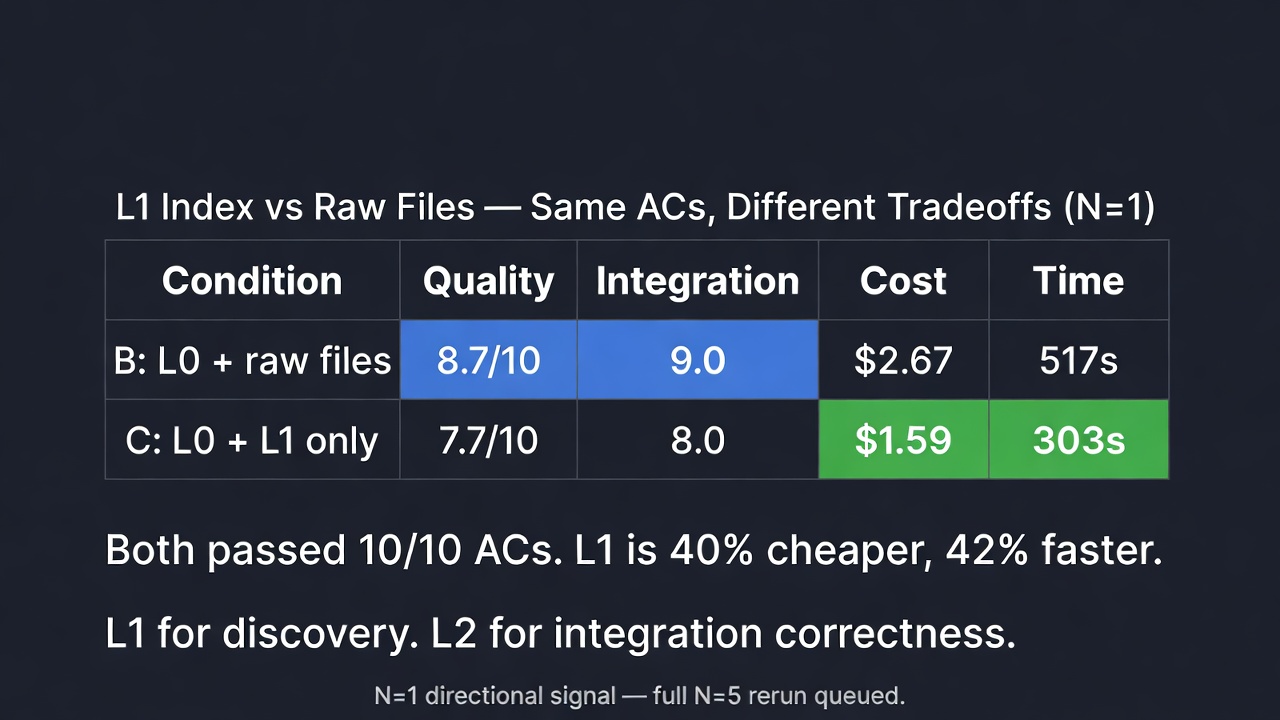
Once the tree was in place, the obvious question: can you skip raw file reads entirely and hand the worker just the L1 JSONs?
We ran a narrow A/B on a platform event-bus task (10 acceptance criteria, spans 6 files):
- B (L0 + targeted raw source files): 10/10 ACs, 8.7/10 quality, integration 9.0, $2.67 total, 517s
- C (L0 + L1 module JSONs, no raw files): 10/10 ACs, 7.7/10 quality, integration 8.0, $1.59 total, 303s (40% cheaper, 42% faster)
Both conditions passed every acceptance criterion. B was higher on integration correctness because the worker saw actual implementations — it wired into the correct existing helpers. C produced working but slightly off-spec integration (used a similarly-named-but-wrong helper because L1 gave it shape without showing which of several candidates was load-bearing).
Caveat: this is N=1, directional signal only. A full N=5 rerun is the next iteration. But the mechanism is clear: L1 captures shape, not behavior. For critical integration work, drop to L2 on the specific files the worker will touch. For fast iteration on well-scoped tasks, L1 alone is enough — and 40% cheaper.
Sub-finding worth flagging: sequential workers hit 98.1% cache read on the second-stage call (4.97M of 5.07M input tokens came from cache). This is why sequential beats parallel on cost — the next worker inherits the prompt the previous one warmed.
The Stacked Numbers
All improvements applied to a large T6 session:

$5.45 → $0.83. -85%. Same model throughout.
The Eight Rules
- Write the CONTRACT first. Always, for any task touching 3+ files. Costs ~$0.15 to generate. Saves 47–54% on the task. Paid back on the first run, every time.
- Don't use Agent Teams for cost-sensitive work. 73–124% more expensive. No quality benefit. Empirically proven across N=5.
- Don't use retry loops. They degrade quality (9→6/10) and cost 2×. The model regenerates whole files when it retries — correct sections disappear. Skip self-evolution entirely.
- Don't add an Opus review pass when your contract is good. Sonnet + CONTRACT already hits 9.8/10. Write a better brief instead of paying for a review.
- Compress your file context with AST extraction. 91% token reduction, zero quality tradeoff.
- Haiku implements, Sonnet authors. Haiku scores 9.0/10 implementing a Sonnet-written contract. Haiku-authored contracts collapse to 4.9/10. Don't conflate the two.
- Drill the index: L0 → L1 → L2. Read L0 first (what exists), L1 per module (exact signatures), L2 only when behavior matters. Never Glob/Grep a codebase that has an index.
- L1 for discovery, L2 for integration. L1-only context is 40% cheaper and sufficient for well-scoped tasks. Drop to raw files on modules where integration correctness matters (N=1 directional).
The CLI
# Install
npm install -g @upgpt/upcommander-cli
# Set your key
export ANTHROPIC_API_KEY=sk-ant-...
# Generate contract + run worker
upcommander run "add pagination to the notes API"
# Or: generate contract first, review it, then run
upcommander contract "add pagination to the notes API"
upcommander run "add pagination to the notes API"
# Quality review on specific files (Opus one-shot)
upcommander review src/app/api/notes/route.ts
# Regenerate the codebase index
upcommander indexThe repo includes: contract generator (Sonnet, ~$0.15 per contract), L0/L1/L2 codebase index (118x compression), AST-summary module (tree-sitter, 12 languages), ephemeral Haiku orchestrator (-96% orchestration cost), worker recipes, and all 52+ benchmark evaluation files in /evaluations.
- GitHub: github.com/UpGPT-ai/upcommander
- npm:
npm install -g @upgpt/upcommander-cli - Full benchmark data:
/evaluationsin the repo — all raw JSON, every run
What's Still Open
- Human quality review — all scoring is model-on-model. Same-family bias acknowledged. Independent human review pending.
- Non-greenfield at scale — all real data is greenfield. Large refactoring at production scale needs its own benchmark series.
- OpenRouter multi-model routing — infrastructure exists, benchmarks pending.
Questions or replications: [email protected]
Frequently Asked Questions
What is a CONTRACT.md in AI-assisted development?
Are Anthropic Agent Teams faster and cheaper than sequential AI workers?
Do retry loops improve AI code quality?
How much do AST compression techniques reduce token usage?
Is Haiku as good as Sonnet for AI coding tasks?
What is the L0/L1/L2 codebase index?
Should you feed L1 index to workers or just raw files?
What is UpCommander?
Related Articles
What We Learned After $45 and 52 AI Coding Benchmarks (The Part That Matters to You)
The biggest factor in AI development cost isn't the model — it's the brief. 52 benchmarks, -85% total cost reduction, explained for decision-makers.
AI AgentsAI Employees vs. AI Assistants: Why the Difference Matters for Your Business
AI assistants help humans work faster. AI employees do the work autonomously. Learn why the agentic workforce model is replacing chatbots and copilots in 2026.